No Pre-Built Map
DREAM operates in dynamic, previously unseen indoor environments from a natural-language instruction.
Mobile manipulation in dynamic indoor scenes
DREAM couples online spatio-semantic memory, hybrid localization, task-oriented navigation, and robust manipulation so a mobile robot can work in previously unseen environments while targets move and the scene changes.
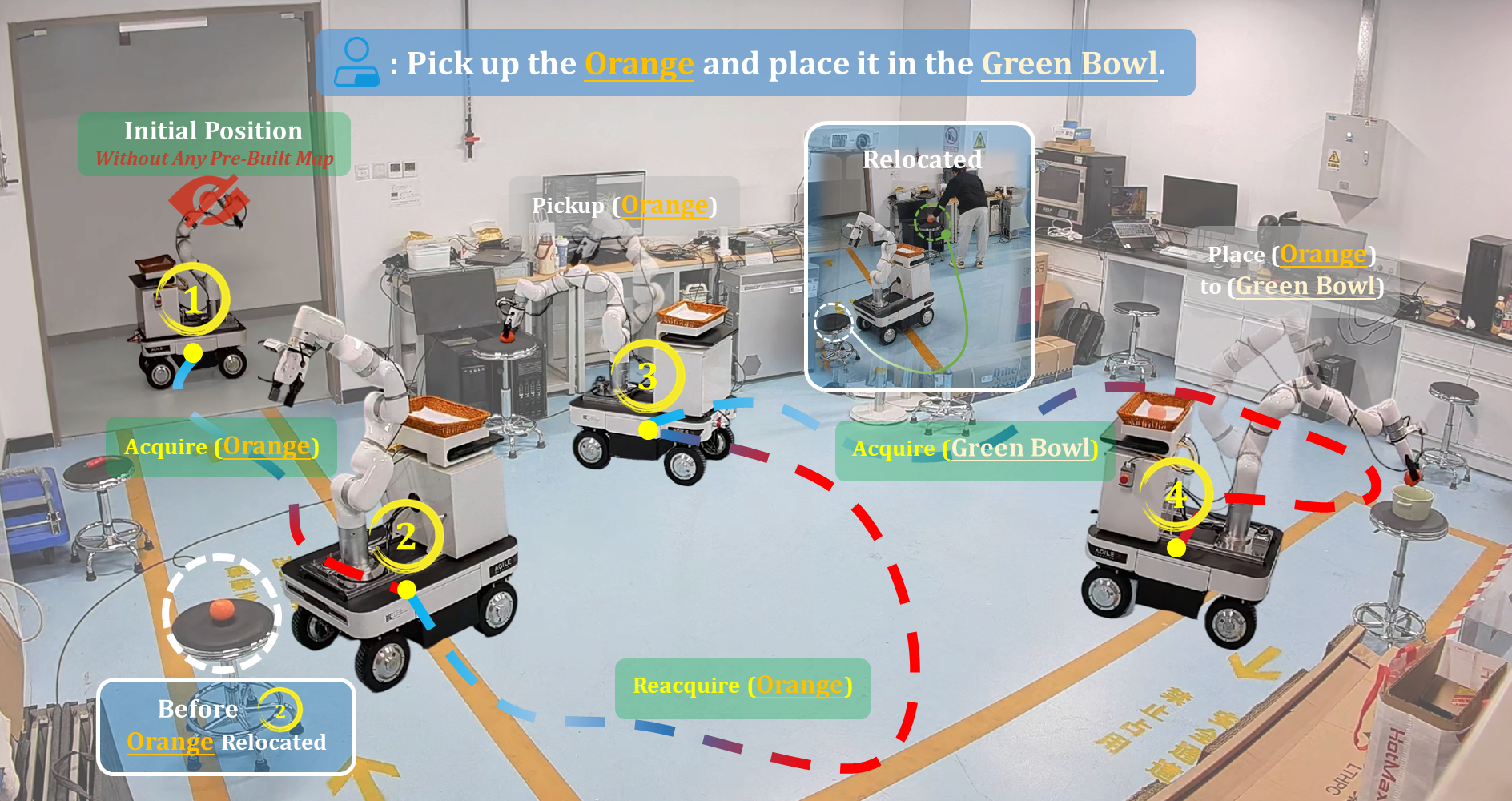
Reliable mobile manipulation in dynamic indoor environments requires a 3D semantic representation that remains consistent with the evolving real world. Most existing systems rely on pre-built maps, assume static environments, or presuppose highly accurate camera poses; when these assumptions break, navigation and manipulation operate on stale information.
DREAM is a mobile manipulation framework for previously unseen indoor environments without any pre-built map. It integrates a lightweight indoor LiDAR-Inertial-Visual SLAM backend with dynamic spatio-semantic memory, Redundancy-Aware Memory Pruning, hybrid localization, task-oriented navigation, and robust grasping and placement strategies.
DREAM operates in dynamic, previously unseen indoor environments from a natural-language instruction.
Online spatio-semantic memory updates voxelized 3D semantics and prunes stale redundant information.
Multi-sensor SLAM and visual loop closure provide temporally consistent poses in dynamic scenes.
The system is evaluated on navigation, pickup, placement, and long-horizon mobile manipulation.
Primary videos
The two combination videos, the more-videos reel, and the SLAM test are the main viewing layer. Each combination video merges three synchronized perspectives so the full task can be understood at a glance, while the SLAM test shows the localization foundation for memory construction and downstream mobile manipulation.
Main demo 01
A compact view of the robot, localization stream, and server-side state for the first long-horizon manipulation sequence.
Main demo 02
A second complete run that highlights dynamic scene updates, reacquisition, and manipulation under changing target layouts.
More videos
Extended behaviors and supplementary runs for understanding how DREAM responds across varied navigation and manipulation conditions.
Robust SLAM
With camera, LiDAR, and mobile-base calibration transforms measured only from CAD files, the SLAM system still achieves high localization accuracy. This robust localization is the core support for memory construction and later mobile manipulation.
Sub videos
These clips are supporting views for the two combination videos. They isolate the third-person recording, SLAM/localization behavior, and server-side interface so each component in the merged demo is easier to inspect.
Three source views used to explain the first combination demo.
Three source views used to explain the second combination demo.
Method
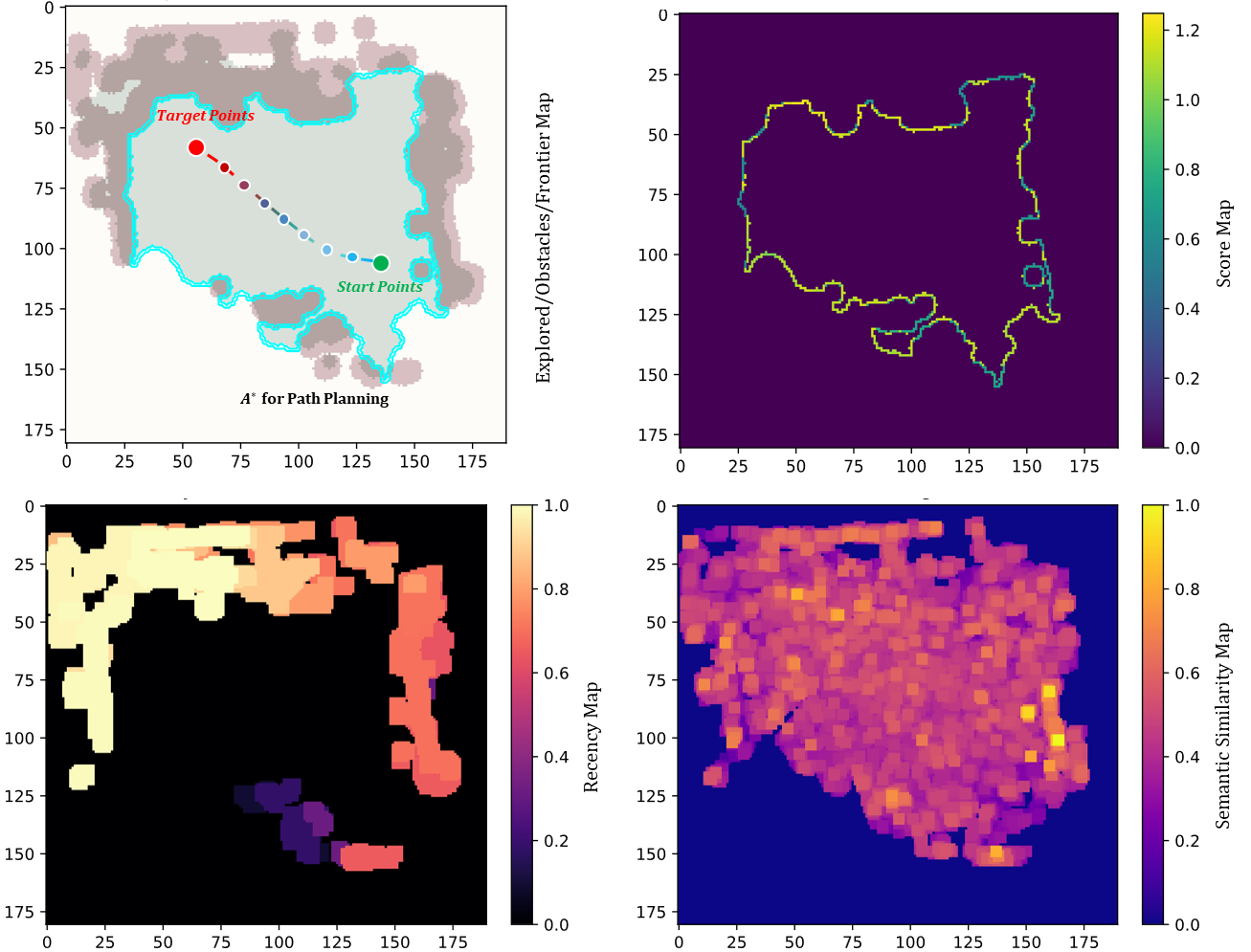
DREAM is organized around a closed loop across perception, memory, localization, navigation, and manipulation.
Hardware platform: AgileX Ranger Mini 3.0 mobile base, UFACTORY xArm6 manipulator, wrist-mounted Intel RealSense D435i RGB-D camera, and Livox MID-360 LiDAR with a built-in IMU.
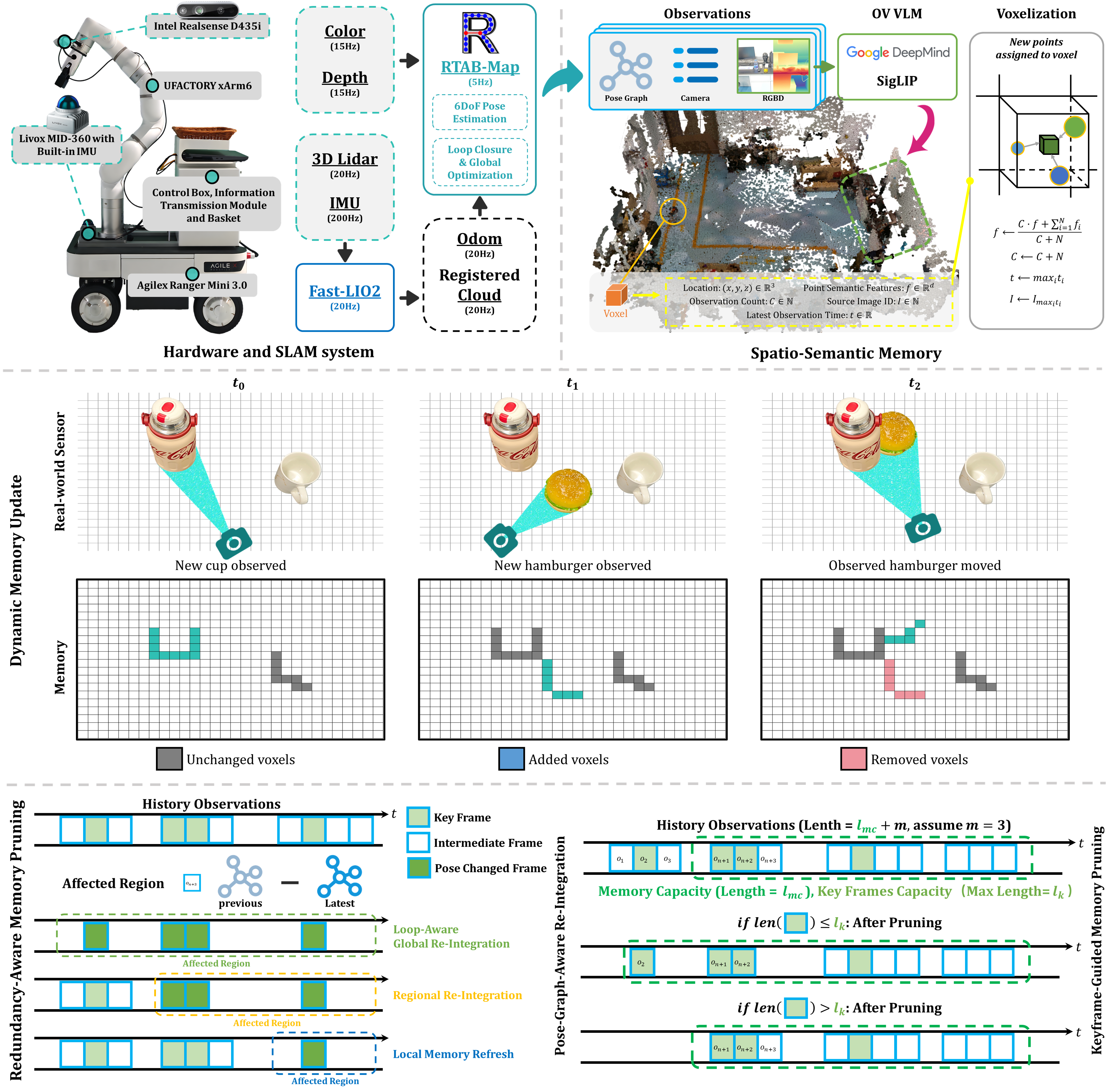
ROBOT.jpg and ROBOT.zip exported from SolidWorks.

Experiments
DREAM is deployed on a real mobile manipulation robot in four dynamic indoor laboratory environments and is evaluated on navigation, pickup, placement, and long-horizon task success.
Navigation success
Pickup success
Place success
Long-horizon success
Across four scenes, DREAM improves long-horizon success by 10-20 percentage points over the DynaMem baseline while using less spatio-semantic memory and computation.
@misc{yan2026dynamicresilientspatiosemanticmemory,
title={Dynamic Resilient Spatio-Semantic Memory with Hybrid Localization for Mobile Manipulation},
author={Zhijie Yan and Shufei Li and Ze Zhang and Xin Liu and Yuhang Zheng and Zuoxu Wang},
year={2026},
eprint={2606.00576},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2606.00576},
}